|
0 Comments
Some people spend their weekends doing housework, socializing, or running errands. I spent last weekend playing with image classification and having a blast with it - so much so that I wrote a blog about the experience. Read it here!  Python has become the darling language of the data science and data engineering world. It's versatile and powerful, yet easy enough for beginners to use. While we encounter Python developers in every area of IT from web development to network management, we're really seeing the boom right now in machine learning and deep learning application development.
But there's a problem where data science and big data intersect as Hadoop does not have native support for Python. On a filesystem like MapR-XD, this is less of an issue since any library that supports parallel computation can use MapR-XD as a Direct NFS storage layer. If you want to leverage Apache Hadoop YARN for distributed computation, however, you are limited to the Spark Python API (PySpark). Read more Executive Briefing: A new taxonomy of machine learning Session details
Rachel Silver shares a new taxonomy of machine learning approaches that distinguishes between those that are providing enormous competitive advantage and those that represent merely small, incremental improvements on existing analytical tools and details a framework for evaluating ML approaches on several dimensions of complexity, including: The amount of data required (such as for training) The computational complexity of the training algorithm Real-time streaming requirements (versus just batch computing) Data throughput for the deployed model to process Rachel explores examples of how to apply this framework to real-world machine learning approaches and highlights the technical requirements of supporting the most disruptive examples of ML solutions. The MapR Data Science Refinery container includes a FUSE-based MapR POSIX Client, optimized for containers, that allows deep learning libraries to read and write data directly to MapR-FS. 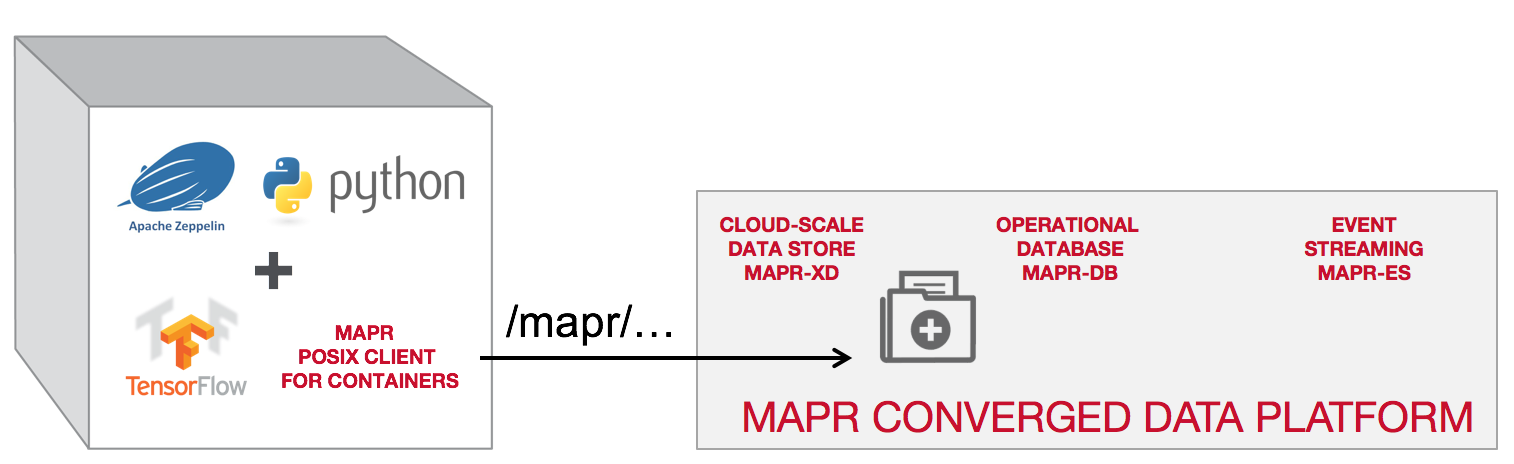 So, when you run TensorFlow, the compute occurs on the host where the container resides, but each container has full access to the persistent storage provided by the MapR Converged Data Platform. When you kill the container off, the data remains. Complete Steps to deploy this can be found here. This was my first time speaking at a public event and I was terribly nervous. Even got through it in half the time! Data Science is a hot topic in boardrooms right now. Everybody wants to adopt AI/ML, hire the best and brightest data scientists, and enable them to experiment and build intelligent applications. New libraries have made it possible to analyze new types of data and even gain new insights from historical data. Massive amounts of data being generated from the boom in IoT computing mean there’s even more demand for ML aggregation at the edge. Everybody wants in.
Read More Are you a data scientist, engineer, or researcher, just getting into distributed processing and PySpark, and you want to run some of the fancy new Python libraries you've heard about, like MatPlotLib?
If so, you may have noticed that it's not as simple as installing it on your local machine and submitting jobs to the cluster. In order for the Spark executors to access these libraries, they have to live on each of the Spark worker nodes. You could go through and manually install each of these environments using pip, but maybe you also want the ability to use multiple versions of Python or other libraries like pandas? Maybe you also want to allow other colleagues to specify their own environments and combinations? If this is the case, then you should be looking toward using condas to provide specialized and personalized Python configurations that are accessible to Python programs. Conda is a tool to keep track of conda packages and tarball files containing Python (or other) libraries and to maintain the dependencies between packages and the platform. Read More... Microservices are simple, single-purpose applications that work in unison via lightweight communications, such as data streams. They allow you to more easily manage segmented efforts to build, integrate, and coordinate your applications in ways that have traditionally been impossible with monolithic applications.
Read More... |
AuthorRachel Silver is a Principal Technical Product Manager Archives
November 2023
|
 RSS Feed
RSS Feed